In SEO, improving crawl budget means that search engines will index new pages and existing page updates more quickly.
This issue shouldn’t concern sites, and John Mueller has said that even 100k URLs shouldn’t impact crawl budget.
However, this can definitely affect midsize companies.
Search engines will generally crawl any URL variation they discover, including those with parameters (question mark, equal sign and/or hash symbols in URL) even if serving no good purpose to search engines or users.
For example, one client has bloat within their Resources section because they have endless categories, many too detailed or making no meaningful change, that can also be combined.
A past client used Google’s indexing API to send countless pages created programmatically from their app, nearly all of them redundant & thin. Google now struggles to find their vital content.
Larger sites in these cases, without proven value in organic search, will need to cut back to “earn” more Google crawls.
Here are 5 tips in these scenarios:
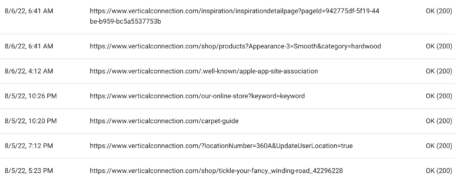
- In Google Search Console, use the Crawl Stats report. How are daily crawl requests syncing up with how many pages you create or update? If possible, you may want to check your server logs to better understand what Google is crawling.
- Ensure all URL parameters are purposeful. Consolidate duplicate content when possible, not just noindex or canonicalize. Ensure self-referencing canonicals so that URL parameter-based URLs don’t get undue attention.
- Maintain a healthy site that lacks many broken links or redirect chains and is fast. This may involve optimizing your server.
- For key pages, ensure meaningful changes compared to existing content if you want that page to rank.
- The <lastmod> tags in your XML sitemap should reflect any changes.
Be selective at first. With more links to your site, or off-page authority, you will increase crawl budget. You may need to prioritize key pages, noindex some, use robots.txt to block access or limit URL parameters, at least initially.